O problema real: tokens custam caro
Se você usa LLMs em escala – seja com agentes de código, RAG ou chains complexas – sabe que o custo por token pesa no bolso. Cada prompt longo, cada log de ferramenta, cada chunk de contexto é drenagem de crédito. E pior: muitas vezes o prompt está cheio de ruído que o modelo nem usa. Até onde vale a pena pagar por tokens que não agregam?
O fato: Headroom promete cortar 60-95% dos tokens
Headroom é uma ferramenta open-source que comprime o contexto antes de enviá-lo ao LLM. O resultado? Mesmas respostas, com uma fração dos tokens. Nos testes públicos, um prompt de 10.144 tokens caiu para 1.260 – e o modelo ainda encontrou o mesmo erro crítico. A promessa é ambiciosa, mas os números pedem verificação.
Como funciona (visão de operador)
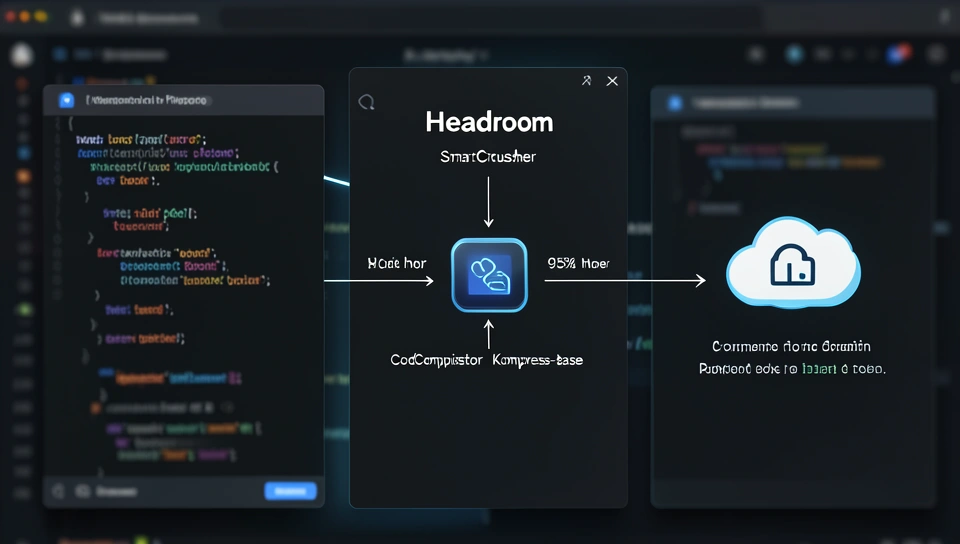
Headroom pode ser usado de três formas: como biblioteca Python/TypeScript, como proxy HTTP ou via MCP. Ele roda localmente – seus dados não saem da máquina. Internamente, usa um roteador de conteúdo que escolhe o compressor certo para cada tipo de dado: SmartCrusher para JSON, CodeCompressor para código (AST-aware), e Kompress-base para texto. Há também um CacheAligner que estabiliza prefixos para aproveitar o cache KV do provedor. A compressão é reversível via CCR – o original nunca é deletado, e o LLM pode recuperar detalhes sob demanda. Em termos de custo: a compressão adiciona latência local (alguns ms) e consome CPU/GPU leve. O trade-off é claro: você troca tempo de compressão por economia de tokens. Para workloads pesados, a economia de custo pode superar a latência extra.
O que isso muda na prática
Quem ganha? Equipes que rodam coding agents (Claude Code, Cursor, Codex) em loops longos – a economia pode ser enorme. Também ganha quem usa RAG com muitos chunks, onde a compressão elimina redundâncias. Quem perde? Quem depende de compressão nativa do provedor e não pode rodar processos locais (sandbox). Ação prática: instale com pip install headroom-ai[all] e teste o wrap no seu agente: headroom wrap claude. Monitore os tokens salvos com headroom stats. Mas não confie cegamente: avalie a precisão no seu domínio.
Tensão: a compressão realmente mantém a qualidade?
Os benchmarks mostram acurácia preservada, mas eles foram feitos em tarefas padrão (síntese, QA, fat-finding). Em cenários criativos ou com nuances específicas, a compressão pode perder detalhes sutis. A pergunta que fica: o ganho de token vale o risco de perder um contexto crítico? Headroom tenta mitigar com a reversibilidade (CCR), mas isso adiciona um round-trip extra se o LLM precisar do original. Na prática, você precisa testar com seus próprios dados e decidir se o trade-off é aceitável. Não é uma bala de prata – é uma ferramenta que exige ajuste fino.
Conclusão
Headroom resolve um problema real – o custo de tokens – com uma abordagem pragmática e local-first. Antes de adotar, teste em um subconjunto do seu workload e meça impacto em latência e qualidade. A economia pode ser grande, mas só você sabe se o modelo que você usa tolera compressão agressiva. E aí, vale o risco?
Nenhum comentário ainda. Seja o primeiro a comentar!
Deixe seu comentário
Comentários passam por moderação antes de serem publicados.